区块链VS分布式数据库:革新与代价
区块链VS分布式数据库:革新与代价
前情提示:本文较为硬核,若有兴趣需耐心阅读,不感兴趣请跳至简言之,喜欢思辨的同学可以跳至悖论,希望对有心之人产生启发~
自2009年比特币正式诞生,到2013年以太坊横空出世,再到今22年的9月15号以太坊即将迎来合并的巨大变革。我们对于区块链的技术的认知越来越趋向“越来越像分布式数据库”发展。
而事实也确实如此,区块链从诞生之初只服务于加密货币,到现在随着智能合约、共识技术的发展,区块链也慢慢被用来服务于通用的数据管理系统。
只不过,在区块链的身上仍散发着这一代人激进与寻求突破的气息。相对于分布式数据库,区块链有很大的革新,但代价也不会小。
如何权衡这样的 “交换”,我将从它们之间的四个差异点(复制、并发、存储、分片)出发。
🌻区块链
区块链最初只是用来服务加密货币,例如比特币和由此衍生的其它加密货币。
在 2014 年,以太坊的出现给区块链带来了智能合约。智能合约的出现,使得区块链上的应用不仅局限于加密货币,还可以支持图灵完全(Turing-complete)的应用计算,这使得区块链逐渐朝着一种通用的去中心化计算平台发展。
从数据结构的角度来看,区块链是一条由哈希指针串联起来的区块链表,每个区块中包含了一系列交易。
从系统的角度来看,区块链是一个由多个互不信任的节点共同维护一个全网一致的账本的分布式系统。
从分布式系统的角度来看,区块链解决了公开网络中的拜占庭(存在恶意节点)共识问题。
- 拜占庭共识问题
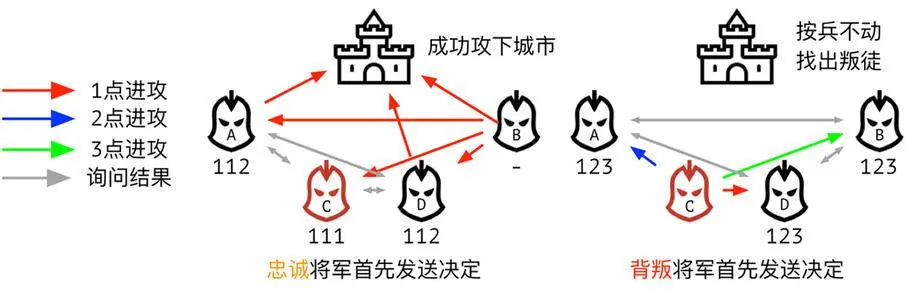
区块链可以分为许可链和非许可链。其中非许可链是完全开放的,每一个人都有资格记账、读取数据,例如比特币、以太坊。而许可链则有一定的准入机制和权限控制,例如国内的蚂蚁链。尽管早期区块链的底层设计与数据库完全不同,但是智能合约应用到了区块链以后,用户能够自由地部署和运行图灵完备的代码,使得区块链与分布式数据库之间产生了可比性。
🌻分布式数据库
分布式数据库是一种数据存储在不同物理位置的数据库。多年来,传统的关系型数据库一直是主流。由于大数据处理和硬件发展等等的现实原因,为了实现系统的高可用性和可扩展性,分布式系统开始进化,在这个新的设计趋势下,出现了NoSQL和NewSQL。
NoSQL 更倾向于提供可用性,而不是一致性。采用 NoSQL 的数据库可以选择多种不同的一致性等级,不同的等级会导致系统表现不同的性能。用户可以根据实际的使用场景在性能和一致性上进行取舍。
NoSQL 的这种设计虽然更加灵活,但加大了上层应用的复杂性,因此一种介于关系数据库与 NoSQL 之间的设计,NewSQL 应运而生。NewSQL 既保留了关系数据库的数据模型以及对 ACID 语义的支持,同时也维持了一定的可扩展性。
🌈代价与革新
区块链小弟在发展中不经意继承了分布式数据库大哥的衣钵,但在“穿衣风格”上,小弟穿的更具有时代更迭的气息,也就是更具有包容性与激进性;如何理解它的包容与激进,如何权衡代价与革新:我将从四个点出发
1. Replication(复制)
首先我要提及复制,对数据进行复制是防止节点失效影响的最直接、最有效的方法。然而复制也将带来一个非常严重的问题——数据一致性问题。
解决数据一致性问题的一个非常经典方式就是状态复制机(state machine replication),即所有节点起始于相同的状态,维护相同的交易日志,于是只要每个节点按照相同的顺序执行每一笔交易,则每个节点的状态也应该是相同的。
实现状态复制机的一个关键技术就是共识算法,而区块链基于分布式数据库的区别之一便是共识算法。
- 在传统的分布式数据库当中,节点属于值得信任的内部系统,因而只需要容忍节点宕机,数据库通常使用CFT协议(Protocols that tolerate crash failures),例如Paxos、Raft;
- 而在区块链中,各个节点需要在互不信任的情况下达成共识,因此需要容忍节点的恶意行为,因此区块链常常会使用代价更大的BFT 协议(Protocols that tolerate Byzantine failures),例如PBFT、PoW等。
- 如下表所示,在故障点数F已知的情况之下,CFT与BFT协议在不同的网络模型当中需要达到的网络规模区别是很大的。
| 同步网络 | 异步网络 | |
|---|---|---|
| CFT | F+1 | 2F+1 |
| BFT | 2F+1 | 3F+1 |
| 由此也可知区块链复制的代价比分布式数据库大很多 |
除了共识算法的不同,区块链和分布式数据库还在复制的级别上存在差异,也就是我们常说的数据粒度。
分布式数据库由于可以依赖一个中心化的“调度员”(这是个可以信赖的系统内部中心),因此在做复制之前可以首先由“调度员”将交易分成更细粒度的指令再分发给不同的节点做复制。
而在区块链中,交易本身并不需要复制到所有节点,负责执行指令的节点也不知道原交易的执行逻辑。然而区块链没有可信赖的中心,于是一般在交易级别做复制,之后再由每个节点执行交易中所包含的所有指令。
简言之
在解决数据一致性上,共识算法是解决问题的根本,但区块链往往需要为了它所谓的去中心化付出更多代价。
2. Concurrency(并发)
并发指的是让交易或事务在同一时间执行。
在传统分布式数据库中,并发控制技术一直是研究热点,好的并发优化能够使得数据库系统的性能大大提升。
而在现有的大部分区块链中,交易仍然是串行执行的。区块链对并发的支持并不友好,主要原因在于,交易执行在很多区块链系统中并非性能瓶颈。例如,在比特币中,一个区块的执行时间在毫秒级,相比于 10 分钟的区块产生时间,执行部分几乎可以忽略不计。其次,由于交易常常会共用合约的状态数据,因而串行执行往往是最简单和保险的方式。
简言之
在并发层面,分布式数据库追求极致的并发以提高性能;而区块链并不支持并发,为了保证节点数据的安全与公正。
3. Storage(存储)
区块链是一个 append-only 的账本,包含了从创世区块开始到最新的区块中包含的全部交易历史,这也就导致了很多主流的区块链的存储量动辄就要上百 GB。为了支持真实性验证,区块链一般采用类似 Merkle Tree 的数据结构存储区块中的交易。
而在大部分的数据库中,除非是有特殊的需求,用户一般只能访问最新的数据。历史数据会以 log 的形式保存一段时间供节点失效恢复的时候使用,但一般会被定期清理掉以节省存储空间。另一方面,由于分布式数据库更在乎性能,因此在建立索引的时候会根据硬件的性质进行特殊的优化。例如,数据在硬盘中一般会以 B+ 树的数据结构存储,而在内存中则用对多核并行和缓存更加友好的 FAST 或 PSL 等结构。
简言之
区块链上的数据是不可篡改的,因此它的存储量将会远超分布式数据库,在主流公链上存储量更是大得可怕。因此在数据结构的选择上,区块链将会选择便于快速数据验证的数据结构如 Merkle Tree ;在分布式数据库上将会选择有利于提升性能的数据结构如B+ 树。
[^Merkle Tree]: 默克尔树,区块链用于数据验证的数据结构。可参考这篇文章Merkle树——验证NFT白名单
[^append-only]: append-only 是计算机数据存储的一种属性,将新数据附加到存储中,但现有数据是不可变的。
4. Sharding(分片)
分片技术是提高数据库可拓展性的关键性技术,它将数据分布到不同的shard当中,由shard中的节点进行处理,从而达到扩展系统或提升处理性能的目的。
然而在区块链中引入shard并不简单,主要有两个挑战
第一,如何进行分片?
我们都知道区块链需要容忍拜占庭错误,而这依赖于一个大前提,即网络中一定比例的节点是诚实的。
例如,在 PoW 中要求总算力的 50% 是诚实的,而 PBFT (实用拜占庭容错算法)则要求超过 2/3 的节点数是诚实的。
在将区块链的网络进行sharding时就需要保证每个shard的安全假设都是成立的,一旦有一个 shard 的安全前提不成立,那么整个系统的安全性都无法保证。
然而由于在sharding的时候一般都是随机将节点分配到不同的shard,这就要求总结点数规模要足够大,而且shard的个数不能过多,这样才能保证每个 shard 中有足够数量的节点保证安全前提能够成立。
第二,如何保证shard之间的原子性?
即一笔交易要么在所有shard都 commit,要么在所有shard都 abort。
shard的原子性要求跨shard的事务在它涉及到的所有shard中要么都提交,要么都中止,表现出行为上的一致性。
- 在分布式数据库中,原子性一般由2PC保证,这需要依赖某个可信的“调度者”。
- 而区块链中缺少这样的协调者,因此会引入BFT协议来协调跨分片交易。
[^2PC]: 2 Phase Commit,两阶段提交协议
简言之
在分片层面,区块链由于需要保证各片区的安全性,它分片的门槛会相对更高,并且仍会有几率组成不安全的整体。并且区块链技术由于缺少可信任的内部中心化调度者,在实现原子性层面上需要使用代价更大的BFT协议。
💎悖论——哲学思考
让我觉得很有意思的一件事就是:区块链致力于实现去中心化,因此就直接舍去了在系统内部的那个可以值得信任的“中心化调度者”。
然而,这样的舍弃必然付出代价,在与分布式数据库做差异对比的时候,区块链在每一个层面都在为自己埋下的伏笔“填坑”,也就是为了去中心化而不得不走“中心化”的老路。
这一点让我不禁一笑,本身在人类社会中,将权利完全下放是一件需要人类文明上升几个维度才可能实现的事,毕竟人心才是最可怕的。
于是我们在区块链中模拟了这样的试验,将权力下放给每一个节点,每个人都是真真正正的平等(仅在公链中)。
让我们来看看试验结果——区块链如今快成了“诈骗”的代名词。有的人骗术高明,因而一夜暴富;也有的人提供平台,可持续性地竭泽而渔,开赌场了属于是;更有的人涉世未深,却想着靠区块链技术暴富,只落得倾家荡产的下场;
虽然完全公平,但这里就像罪恶都市,一切贪婪,犯罪,欺骗,在这里统统被无条件地放大。
回到上文提及的系统内部“中心化调度者”,实际上只要这样的“中心化调度者”的操纵者拥有一颗“纯洁的心灵”,纯洁到公平地对待一切处理,那么区块链技术将没必要存在,也不可能被发明,但现实生活中我想不会存在这样的人吧。
因此,我最想说的是,我们设法用技术的革新来填补人心的无底洞,然而得到的却是——从一个人的贪婪走向一群人的贪婪。
🌙走向融合
随着区块链技术逐渐走向落地,无论是工业界还是学术界都在致力于提高区块链的性能,其中借鉴分布式数据库中成熟的技术则是最简单和保险的做法。例如,BlockchainDB 和 FalconDB 就在区块链系统的基础上引入数据库的 feature,使得互不信任的多方可以共同参与维护一个可验证的数据库。
另一方面,区块链所具备的一些安全特性也受到了一些数据库设计者的青睐,使得一些新型的更加追求安全性的数据库也具备了区块链的基因。例如,Blockchain Relational Database 就是在 PostgreSQL 的基础上引入区块链中所具备的去中心化和可追溯的特性所设计的新型关系数据库。
📕参考文献
[1] Blockchains vs. Distributed Databases: Dichotomy and Fusion: Blockchains vs. Distributed Databases: Dichotomy and Fusion
[2] Casper: ethereum/casper
[3] BlockchainDB - A Shared Database on Blockchains: http://www.vldb.org/pvldb/vol12/p1597-el-hindi.pdf
[4] FalconDB: Blockchain-based Collaborative Database: http://www.cs.utah.edu/~lifeifei/papers/falcondb.pdf
[5] Blockchain Meets Database: Design and Implementation of a Blockchain Relational Database: http://www.vldb.org/pvldb/vol12/p1